从这节课开始,我们就正式进入项目的第二阶段,来用TextCNN实现商品问题的多分类,和“问题加答案”整体的情感分析,这样两个模型的搭建。
前面课程当中,给大家讲解了用 Bert+TextCNN,实现新闻文本分类的项目,这个项目是一个单标签的任务。
但在实际项目中,多标签也是一个比较常见的场景。所以从这节课开始,我们给大家补充一个多标签的处理方案。并且在最后,我们把多标签和单标签两个模型结合起来,做一个 pipline 的联合模型,来提高整体的模型准确率。
数据集
这个多标签任务的数据集,是我工作中实际的项目场景,我们发动业务人员,帮我们手动标注了一些数据,我提取了一部分,供我们学习使用。
数据来源:是用爬虫爬取的淘宝、京东平台上,面霜类商品问答数据。爬虫的内容如果大家感兴趣,也可以留言给我,后续再给大家做补充。
数据量:训练集1w,测试集2k。
类别标签(12个):功效、适⽤⼈群、使用方法、使用感受、不良反应、属性、竞品对比、包装、价格、渠道、物流、其他。
数据示例
可以祛斑吗? 功效 小孩能不能用? 适用人群 可以祛痘吗,有没有副作用? 功效|不良反应 有没有刺激性?会过敏吗? 不良反应
算法实现
跟单标签分类类似,我们继续沿用 Bert+TextCNN 来提取句子特征,不同的点,在于单标签目标值是一个分类的id,多标签的目标值是一个序列。
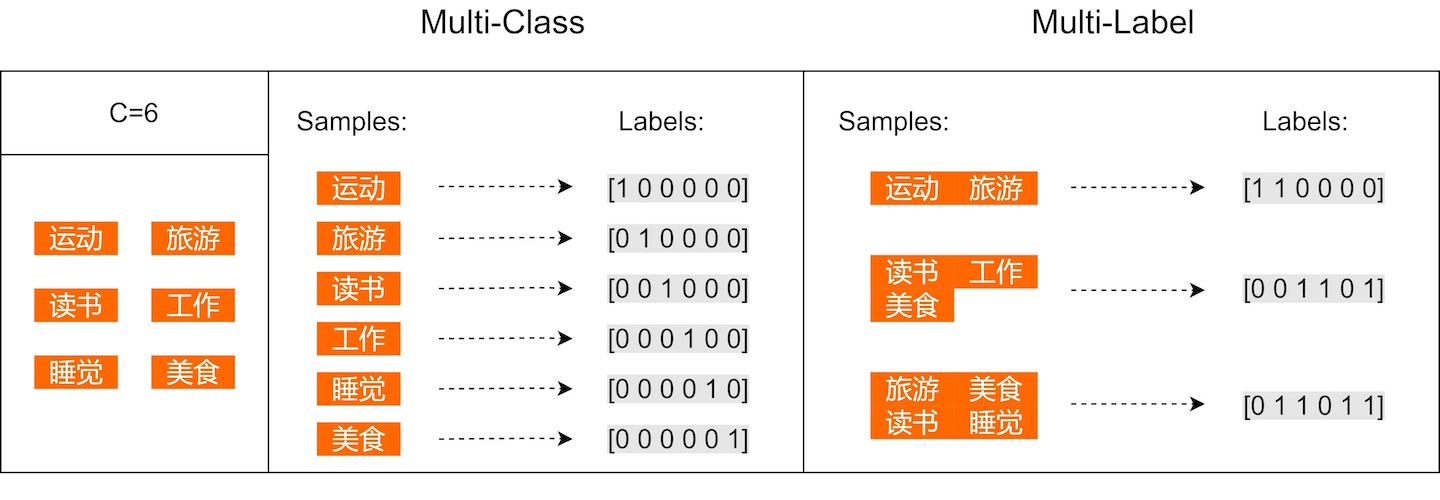
好,这节课我们先给大家介绍了,多标签任务用到的数据集,然后简单介绍了算法实现的方案,那下节课,我们还是先来处理一下数据集,然后把之前的新闻数据集,换成自己标注的问答的数据。
本文为 陈华 原创,欢迎转载,但请注明出处:http://edu.ichenhua.cn/read/505



