上节中,一起手写了KNN算法,算法本身不难,但比较麻烦。在真实开发场景中,一般都是使用调包的方式,来处理类似大众化的问题。本节介绍使用sklearn实现KNN算法,并针对KNN算法存在的问题,使用KDtree算法进行一个简单优化。
基础代码
from sklearn.neighbors import KNeighborsClassifier import numpy as np # 定义数据 kiss = [104, 100, 81, 10, 5, 2] fight = [3, 2, 1, 101, 99, 98] labels = [1, 1, 1, 2, 2, 2] test = [90, 18] X_train = np.array([kiss, fight]).T y_train = np.array(labels) # 调包训练 knn = KNeighborsClassifier(n_neighbors=5) knn.fit(X_train, y_train) test_X = np.array([test]) pred_y = knn.predict(test_X) print(pred_y)
KDtree简介
KDtree是一种对n维空间的实例点进行存储,以便对其进行快速检索的树形结构。KDtree是二叉树,构造KDtree相当于不断的用垂直于坐标轴的超平面将n维空间进行划分,构成一系列的n维超矩阵区域。
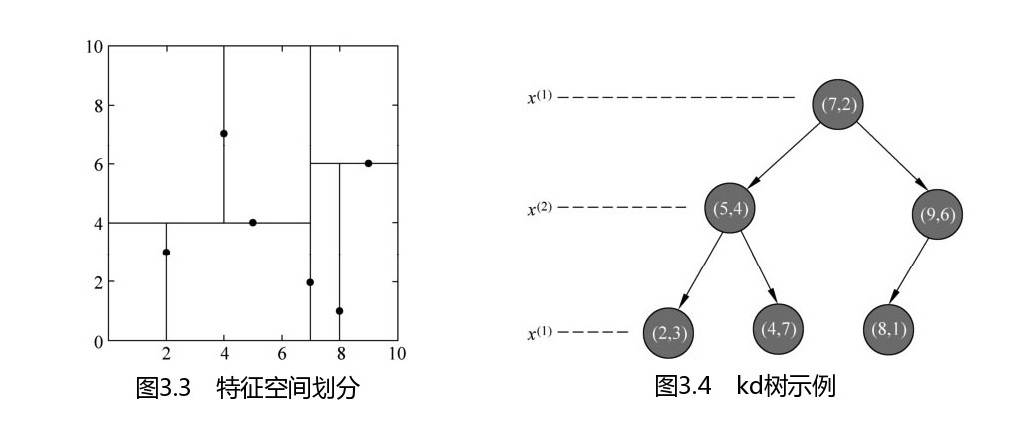
KDtree的构建过程
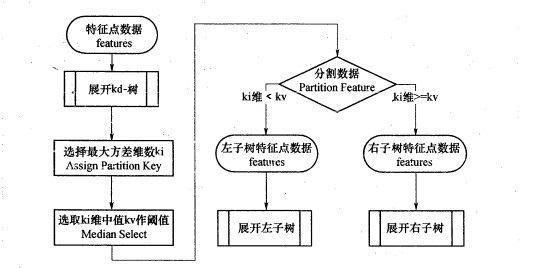
构建示例
T = [(2,3), (5,4), (9,6), (4,7), (8,1), (7,2)]
参考书:李航《统计学习方法》
参考文档:http://t.zoukankan.com/huangyc-p-10294307.html
优化代码
knn = KNeighborsClassifier(n_neighbors=5, algorithm='kd_tree')
本文为 陈华 原创,欢迎转载,但请注明出处:http://edu.ichenhua.cn/read/232
- 上一篇:
- 手写AI算法之KNN近邻算法
- 下一篇:
- 手写AI算法之TF-IDF关键词提取



