K近邻(K-nearst neighbors, KNN)是一种基本的机器学习算法,所谓k近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。比如:判断一个人的人品,只需要观察与他来往最密切的几个人的人品好坏就可以得出,即“近朱者赤,近墨者黑”。
KNN算法既可以应用于分类应用中,也可以应用在回归应用中。KNN在做回归和分类的主要区别,在于最后做预测的时候的决策方式不同。 KNN在分类预测时,一般采用多数表决法;而在做回归预测时,一般采用平均值法。
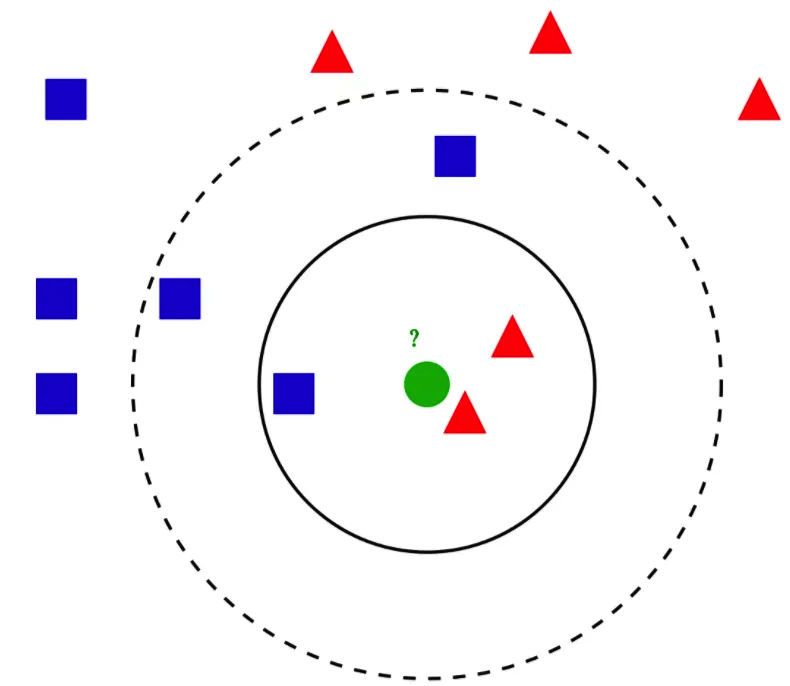
一、KNN的算法步骤
1、从训练集合中获取K个,离待预测样本距离最近的样本数据;
2、根据获取得到的K个样本数据,来预测当前待预测样本的目标属性值。
二、三个重要因素
1、K值的选择:一般根据样本分布,选择一个较小的值,然后交叉验证,来选择一个合适的最终值。K值太小,容易过拟合,K值太大,容易欠拟合。
2、距离的度量:一般使用欧式距离。
3、决策规则:在分类模型中,主要使用多数表决法或者加权多数表决法;在回归模型中,主要使用平均值法或者加权平均值法。
三、代码示例
根据电影中接吻和打斗次数,判断电影类型。
1、定义数据集
kiss = [104, 100, 81, 10, 5, 2] # 接吻次数 fight = [3, 2, 1, 101, 99, 98] # 打斗次数 labels = [1, 1, 1, 2, 2, 2] # 电影类别:1-动作电影 2-爱情电影 test = [90, 18]
2、定义KNN处理类
class Knn():
def __init__(self, k):
self.k = k
def fit(self, X_train, y_train):
self.X_train = X_train
self.y_train = y_train
def perdict(X):
pass
3、模型实例化
import numpy as np knn = Knn(3) # 一般用奇数 X_train = np.array([kiss, fight]).T y_train = np.array(labels) knn.fit(X_train, y_train)
4、按最小距离分类,并返回分类
from collections import Counter
def perdict(self, X):
res = []
for x in X:
# 求欧式距离
dists = [((x-x_t)**2).sum()**0.5 for x_t in self.X_train]
idxs = np.argsort(dists)
# 找到前k个id对应的y值
ls = self.y_train[idxs[:self.k]]
# 统计数量,取最多
res.append(Counter(ls).most_common()[0][0])
return np.array(res)
# 模型预测
X_test = np.array([test])
res = knn.perdict(X_test)
print(res)
本文为 陈华 原创,欢迎转载,但请注明出处:http://edu.ichenhua.cn/read/233



