前文介绍了文本向量化类 Gensim.Word2Vec 的用法,本文继续用 Word2Vec 写一个小案例,用《人民的名义》小说文本,来训练一个Word2Vec,分析小说中人物的姓名文本相似度。
当然,本文只是基于Word2Vec可视化文本特征,并不是做人物关系图谱,任务关系会在后面介绍。
代码示例
1、jieba分词并去停用词
import jieba
# 加载停用词表
stopwords_str = open('./datas/stopwords.txt').read()
stopwords = stopwords_str.split('\n')
# jieba添加自定义词语,防止误拆
name_list = ['沙瑞金', '田国富', '高育良', '侯亮平', '钟小艾', '陈岩石', '欧阳菁', '易学习', '王大路', '蔡成功', '孙连城', '季昌明', '丁义珍', '郑西坡', '赵东来', '高小琴', '赵瑞龙', '林华华', '陆亦可', '刘新建', '刘庆祝', '赵德汉']
for name in name_list:
jieba.add_word(name)
# 分词并过滤停用词
text = open('./datas/in_the_name_of_people_all.txt').read()
words = jieba.lcut(text)
words_list = [word for word in words if word not in stopwords and len(word) >= 2]
2、训练Word2vec模型
from gensim.models import Word2Vec
model = Word2Vec([words_list], vector_size=20, min_count=1)
wv = model.wv
vocabs = []
vectors = []
# 防止人物没有出现报错
for name in name_list:
try:
vocabs.append(name)
vectors.append(wv[name])
except:
pass
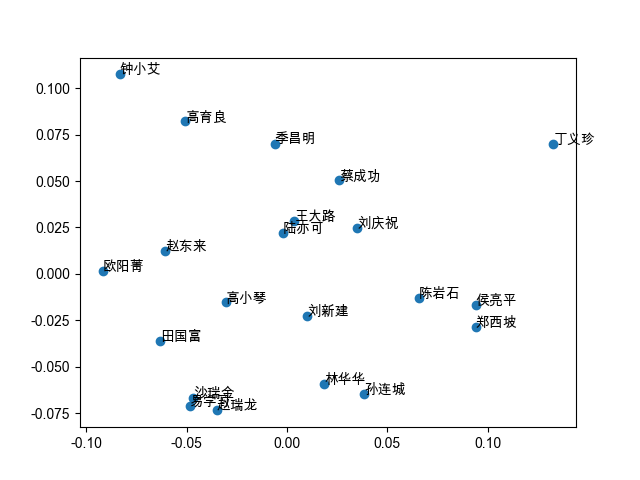
3、PCA降维并可视化
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# PCA降维
pca = PCA(2)
vec_dr = pca.fit_transform(vectors)
# print(pca.explained_variance_ratio_)
# 降维后只携带了原始特征的0.4的信息,可视化效果不佳
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
# 可视化
plt.scatter(vec_dr[:, 0], vec_dr[:, 1])
for w, (x,y) in zip(vocabs, vec_dr):
plt.annotate(w, (x,y))
plt.show()
本文为 陈华 原创,欢迎转载,但请注明出处:http://edu.ichenhua.cn/read/315



